Fixation Prediction and Eye Movement Control
You can find our code on GitHub, including a dockerized version for download.
Introduction
Humans frequently move their eyes in rapid jumps known as saccades, shifting their gaze from one point of fixation to the next. Points of fixation over an image can be recorded for a human observer using an eye tracker, and the particular sequence of fixations which a person executes when viewing an image provides a strong indication of the locations attended.
One of the dominant domains of computational research in fixation prediction is the saliency model. A saliency model is an algorithm which produces a saliency map, a 2D representation of the likelihood that a specific region of an image will be fixated by a human observer. While the past two decades have seen the development of a large number of saliency models and a great deal of research into their performance and characteristics, the nature of a saliency map is fundamentally static. It provides what could be viewed as an expectation map of the probability that a random observer will fixate a particular location in an image, but does not provide a strong prediction as to the specific ordered sequence with which locations might be targeted.
This project seeks to extend the concept of a saliency map to a more complete model of eye movement control and fixation selection. It takes into account a number of characteristics not normally accounted for in saliency models, such as retinal anisotropy, central and peripheral cortical processing differences, and the spatiotemporal dependency between fixation locations.
A Qualitative Example

The above example provides a qualitative display of our model (STAR-FC) in comparison to a selection of saliency models of fixation prediction. (a.) shows the original input image, the painting Morning in a Pine Forest by Ivan Shishkin. (b.) shows the human fixation trace recorded by Yarbus (1967) during two minutes of recording. (c.) shows the output of our model, STAR-FC, simulating two minutes of viewing. (d.)-(f.) shows the extracted fixation sequence from a selection of classic saliency models, while (g.)-(i.) shows the extracted fixation sequence from a selection of state-of-the-art deep learning models. As can be seen, STAR-FC provides a much more human-like pattern of fixation, whereas the other models fail to capture the sequence structure of the human observer.
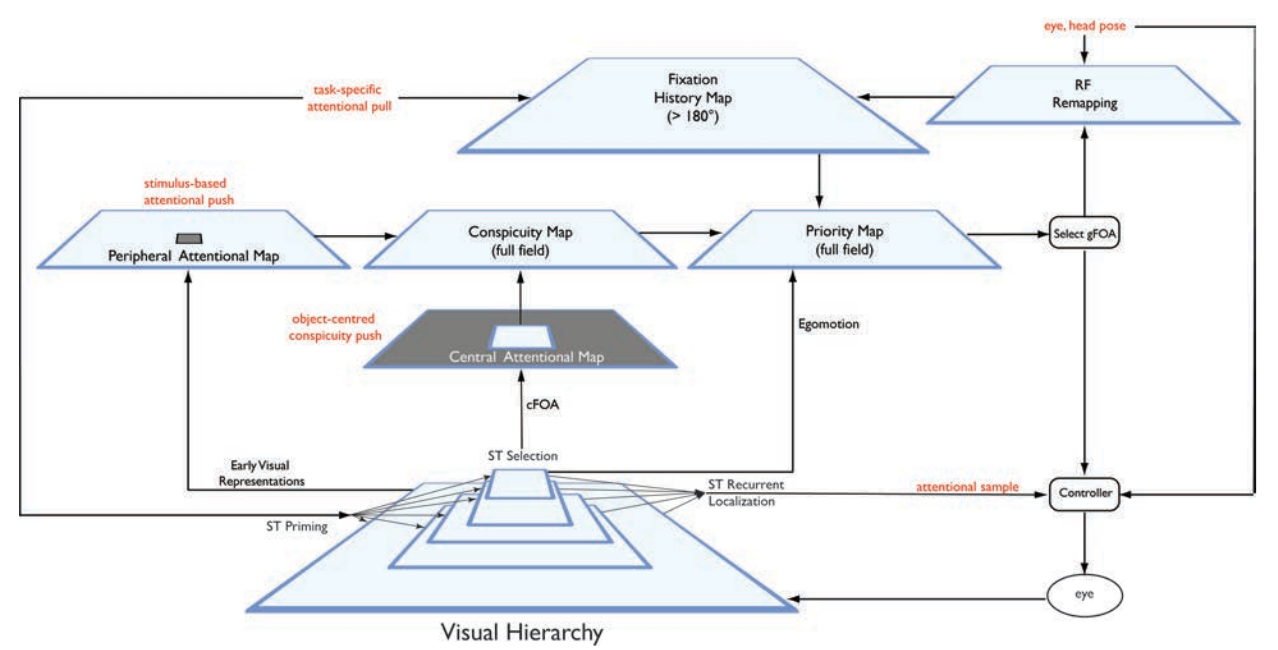
Theoretical Model
A theoretical formulation of our model can be found in the diagram to the right, and you can find more details in our paper in the Journal of Eye Movement Research.
Practical Implementation
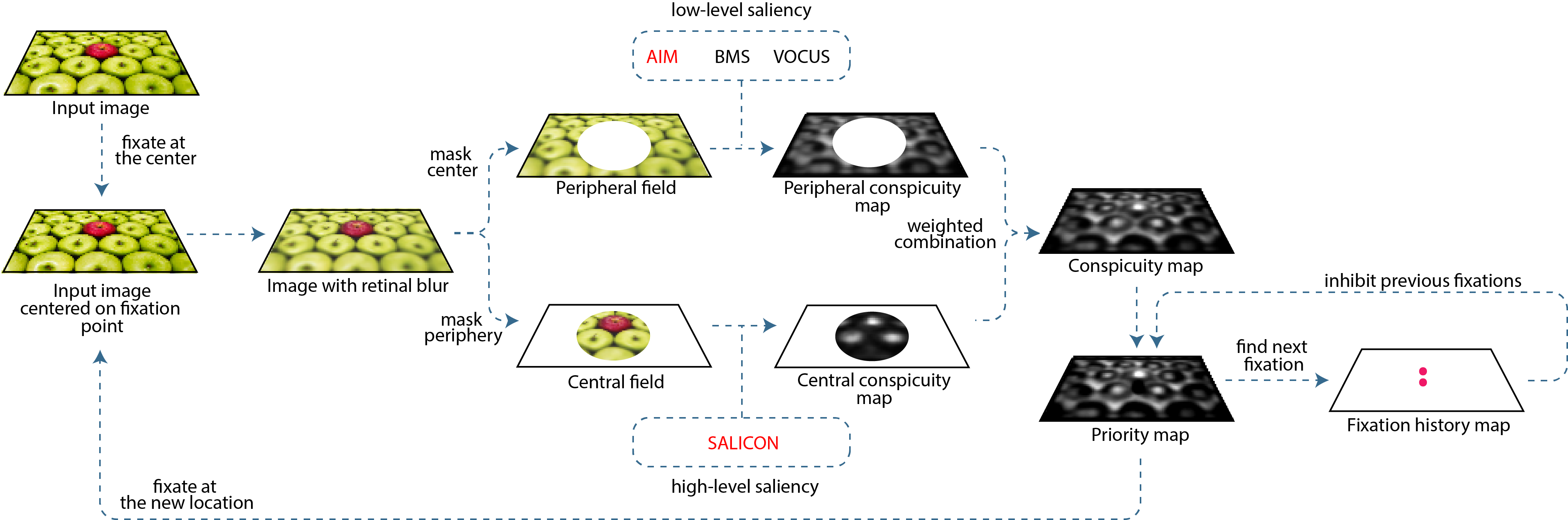
The diagram above provides a schematic overview of the implementation used in our paper presented at the Computer Vision and Pattern Recognition 2018 conference. You can download our code from GitHub either by following the link at the top of this page or by clicking on the GitHub logo to the right.
