A Few Examples
To start with, the key is representation. The full power of ST is not seen in a ‘flat’ representation, such as a representation of edges, for example. One needs to define a representation of visual information as a pyramid. Each layer features spatial resolution reduced from the previous yet visual information at a higher level of abstraction. This is exactly how visual representation is organized in the brain (see Guy Orban’s paper Higher Order Visual Processing in Macaque Extrastriate Cortex, Physiol Rev 88:59-89, 2008, for an up-to-date view of the kinds of features and concepts represented at each layer of the macaque’s visual cortex). A single pyramid will not suffice; it certainly does not for the brain and as a result one must think about how to incorporate many different kinds of visual information, or visual features, into a structure with a single input layer yet several output representations. Something like this....
Each of the different colours here caricatures a separate pyramid (with some number of intermediate layers) computing a different kind of visual feature. Our example below includes 78 output representations and a total of 690 different feature types in 6-layer pyramids above the image layer.
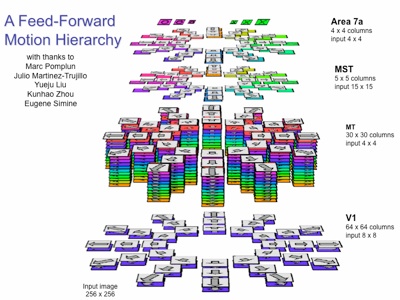
We built a motion processing hierarchy on which to test Selective Tuning. V1 is selective for motion translation, 12 directions and 3 speed bands. Layers MT, MST and 7a have abstracted versions of translation as well. MT includes speed gradients, MST pattern motion, and 7a abstractions of pattern motion plus full field motion.
For more examples and explanations of these, see
-
•Tsotsos, J.K., Culhane, S., Wai, W., Lai, Y., Davis, N., Nuflo, F., Modeling visual attention via selective tuning, Artificial Intelligence 78(1-2), p 507 - 547, 1995.
-
•Tsotsos, J.K., Culhane, S., Cutzu, F., From Theoretical Foundations to a Hierarchical Circuit for Selective Attention, Visual Attention and Cortical Circuits, p. 285 – 306, ed. by J. Braun, C. Koch, and J. Davis, MIT Press, 2001.
-
•Tsotsos, J.K., Liu, Y., Martinez-Trujillo, J., Pomplun, M., Simine, E., Zhou, K., Attending to Visual Motion, Computer Vision and Image Understanding, Vol 100, 1-2, p 3 - 40.
-
•Rodriguez-Sanchez, A.J., Simine, E., Tsotsos., J.K., Attention And Visual Search, Int. J. Neural Systems, 2007,17(4):275-88.
-
•Rothenstein, A., Rodriguez-Sanchez, A., Simine, E., Tsotsos, J.K., Visual Feature Binding within the Selective Tuning Attention Framework, Int. J. Pattern Recognition and Artificial Intelligence - Special Issue on Brain, Vision and Artificial Intelligence, (in press).
Some examples follow showing how Selective Tuning performs using the above pyramid representation of motion tuned cells.
On the left is an image sequence showing rotating square of noise embedded in noise. In other words, this is an example of pure motion defined form. There is no form information at all. On the right is the analysis hierarchy shown earlier in the page.
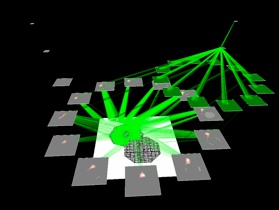
The first image of the sequence on the right reflects the result after the feedforward pass using the input sequence. Although not visible in this movie, the maximum response at the top layer correctly represents the motion category, i.e, rotating clockwise and receding at a medium speed. This demonstrates 2 very important characteristics of ST: ST’s output is consistent with the many observations that show how humans can detect and categorize isolated visual stimuli with a single feedforward pass; and, the motion representation used is significantly more powerful than those in common use that perform only on translation motion and would be blind to the motion in this example.
The movie continues to show the top-down selection process. The colour of the ‘beam’ is the motion pattern type (in the MST layer above), and one can see how the different spatial elements of the motion are selected from within each layer. All of the components of motion eventually converge in the input layer and the result segments the moving square neatly from the noise.
An additional example of pure motion-defined form classification and localization follows. This is a real image sequence, not synthetic, created by using ‘puck’ robots camouflaged using circular cutouts of the background as shown to the left below. The movie on the right shows a single translating puck; the tracking and localization is quite good and has not been ‘cleaned’ in any way, reflecting the complete result of downward tracing of connections through the network (the colour denotes the direction and speed using a coding scheme that is explained in Tsotsos et al. CVIU 2005).

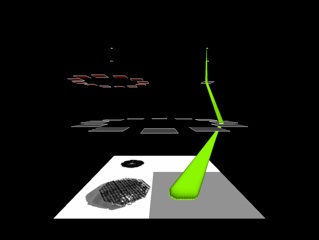
Suppose there are two hexagonal textured objects in an image sequence (see below). The upper item is rotating in place, the lower one is translating, crossing over and occluding the other.

The left image shows the selection of the rotating object ad the right the selection of the translating one after the the first is inhibited. In both cases the colour of the beam reflects the motion category.
Suppose now there are three hexagonal textured objects (see below). The large one in the lower left of the image is translating towards the upper right while rotating, the top one is rotating, and the small one on the right is translating to the left. There is no representation in the system for the combined motions of the large item.
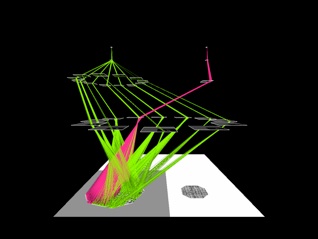
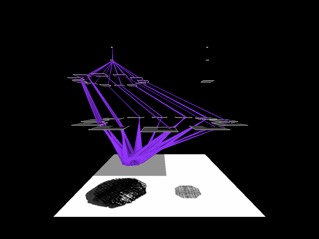
The topmost image shows the first fixation, the middle the second, and the bottom image the third fixation. It is clear that the model correctly finds each object, localizes it properly, and identifies the motion category (by colour). Of interest is the left image; the object that has a compound motion causes no difficulty. The motion pattern and translation portions o the motion hierarchy analyze the input independently and selection can proceed along each dimension separately yet still converge on the same object.