Attention, Binding and Recognition
The use of the three simple words attention, binding and recognition in the title of this section obscures their complexity. As can be seen at my Visual Attention page, there are many attentional mechanisms and it is my claim that experimental work mostly addresses visual performance phenomena that require combinations of several mechanisms thus never clearly showing the characteristics of any one mechanism.
Similarly, although the word recognition is used commonly, it has come to mean any of a number of visual tasks. However, as a careful read through the well presented material in Detection Theory: A User’s Guide, by Macmillan and Creelman (2005) reveals, the range of visual tasks involving recognition of some form is quite large. They define recognition very narrowly as shown in the partial task taxonomy below:

This taxonomy is much larger, but recognition-like tasks appear throughout although all differing in terms of stimulus presentations, task instructions, and so on.
In computer vision, the term recognition is used commonly to mean more than what is shown above. A model of ‘recognition’ therefore, can mean different things to different people. And especially when claims are made of relevance to human visual recognition, interpretation is everything.
Binding shares the same fate, but perhaps even worse. Classically, binding has been regarded as a problem of correctly linking location with visual feature (or other modalities - binding is a broad issue). This makes the tacit assumption that location is somehow represented in the brain without feature and vice versa. But there seems to be no evidence for this within the usual visual areas associated with recognition (see Tsotsos et al. 2008). What is true is that location is partially abstracted away, not eliminated entirely, and remains associated with features. The more complex the feature the more abstract is the location information associated with it. This then requires a whole new perspective on the binding problem. The task and the nature of the features to be bound dictates the kind of location information to be determined.
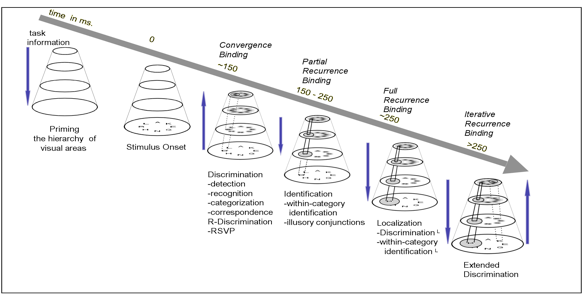
Regardless of visual task, it is the same pair of eyes, the same retinal cells, the same, LGN, V1, V2 and so forth, that process all incoming stimuli. Each step in the processing pathway requires processing time; no step is instantaneous or can be assumed so. In experiments such as those defined above, the timing for each of the input arrays is manipulated presumably in order to investigate different phenomena. There are many variations on these themes and this is where the ingenuity of the best experimentalists can shine. The argument I make is to use time as an organizational dimension, that is, the most effective way of carving up the problem is to cut along the dimension of time. The figure below is is the main descriptive vehicle that ties recognition,
attention and binding together along time course, time course that is observed experimental for the wide variety of visual tasks (as shown in Macmillan and Creelman). This is further developed in Tsotsos et al. 2008, Tsotsos 2008, Rothenstein et al. 2008, Rothenstein et al. 2007.
References
Tsotsos, J.K., Rodriguez-Sanchez, A., Rothenstein, A., Simine, E., Different Binding Strategies for the Different Stages of Visual Recognition, Brain Research 1225, p119-132, 2008.
Rothenstein, A., Rodriguez-Sanchez, A., Simine, E., Tsotsos, J.K., Visual Feature Binding within the Selective Tuning Attention Framework, Int. J. Pattern Recognition and Artificial Intelligence - Special Issue on Brain, Vision and Artificial Intelligence, 22(5), 2008 p. 861-881.
Tsotsos, J.K., What Roles can Attention Play in Recognition?, 7th International Conference on Development and Learning, Monterey, California, August 9-12, 2008. doi 10.1109/DEVLRN.2008.4640805
Rothenstein, A., Tsotsos, J.K., Selective Tuning: Modeling the dynamics of feature binding during object-selective attention, 4th International IJCAI Workshop on Attention in Cognitive Systems, Jan. 8 2007, Hyderabad, India.