Motion Understanding
My interest in visual motion began with my introduction to it by my MSc supervisor, Prof. John Mylopoulos, and his almost completed PhD student Norman Badler, in late 1974. I think it is correct to say that the very first major piece of research on the computer interpretation of motion from
image sequences was the 1976 Ph.D. thesis of Norman Badler at the University of Toronto. I make this claim because he first connected motion features with complex, abstract, spatio-temporal concepts within an algorithm that was tested computationally on image sequences (synthetic). Thus, although many had used image sequences previously, the works that assume constancy of time-varying features over the sequences and were highly application dependent (such as cloud tracking) should be distinguished from those that consider discontinuities over time and hypothesize a general solution. Badler described a methodology for producing conceptual descriptions of three-dimensional time-varying visual scenes. He began with two-dimensional coordinates of object features and described them at successively higher levels of abstraction. He developed a representation for objects and events based on adverbs and prepositions that characterize direction and higher order natural language terms to cover the notions of repetition and event sequences. At the highest level he had specific motion verbs. It is surprising how much of the vision community has interpreted his work as having more relevance for natural language than for visual motion understanding. The verbs are simply the most natural, best-understood and most readily accessible way humans have of communicating motion and time-varying concepts. The fact that no subsequent work has found any other high level representational concepts as replacement is testament to this. The use of verbs as descriptors has been ‘independently’ re-discovered several times since. The overall strategy is one that held great promise then and I feel still does. It certainly laid the foundation for all motion description work that followed.
It was my job to continue this development for my MSc and then for my PhD as well. My first paper on interpretation of visual motion was presented at the 1977 International Joint Conference on Artificial Intelligence, held at MIT. There, I focussed on the emerging semantic representation that I developed for motion concepts, on the kind of interpretation control strategy that would use this representation and even mentioned the issue of possible combinatorial explosion that the work might face. Also at that IJCAI conference, I presented the application domain that I would test my motion understanding system on, image sequences of the human heart (see ALVEN for more detail). Although researchers in the pattern recognition community had been considering heart images for a few years previously, this was the first instance of this domain in the Artificial Intelligence community. The domain was ideal because it was non-trivial, required a rich representation of complex motion concepts and presented difficult computer vision issues as well.
What do I mean by ‘motion understanding’? It is easy to say what I do not mean. I do not mean blind classification, the most common goal of most modern computer vision. Modern computer vision attempts to solve, among other problems, the classification problem, From a large database of exemplars, discover or learn the classes of information (and their boundaries) that can partition those exemplars. Although one might have a functioning computer program that performs a task with high degree of success, one has not learned anything at all about the underlying mechanisms by considering only a statistical relationship. And if the design of the set of exemplars is not carefully considered so that it has appropriate statistical properties (is the set of possilibites/variations in the domain well-defined? does the set span the full range of possibilities? does the set include an equal number of samples of each variation?), good performance is somewhat meaningless and does not generalize. An analogy with medicine makes this point clear: it is one thing to say that a diet high in fat is unhealthy because it is associated with higher incidence of heart disease and cancer and a completely different thing to understand the physiological mechanisms that underlie that association. In the data association case, one can only suggest that one eliminate fat from the diet. If one has a deep causal understanding, one might be able to develop medicines or other interventions that target the precise mechanism along the path from dietary intake to disease that is responsible for the problem. If perhaps there is more than one mechanism on the path, to target one distinctly from the rest. Modern medicine seeks to achieve the latter and only if that deep understanding is not yet available, resorts to the former kind of recommendation.
By visual motion understanding I mean analysis of visual motion that results in an explicit representation of the motion information in such a manner that a human might be able to inspect, question, and interact with that representation. Not quite a causal description, but certainly much more than simple, unrelated, classes of motion. Representations that are explicit would include multiple levels of abstraction, multiple spatial and temporal scales of description, details in space and time about the characteristics of the observed motions, and would provide all of this in an organized, accessible, and examinable manner. In the heart application for example, if the resulting system is to be used for actual diagnosis no trust could ever be developed in the system’s results unless a physician could check conclusions, even query and converse with the system as he might with a consulting colleague, in order to ensure validity on a case-by-case basis. Statistical accuracy of the results does not suffice in life-and-death decisions, which are always considered on a case-by-case basis. Outliers do happen in real life.
Key elements of the solution strategy were the representation and the interpretation control method.
The representational elements were organized along 4 dimensions: spatial parts, temporal parts, specialization, and competitors. Organizing the spatial components of an object in a hierarchy is the most intuitive of these perhaps. Since this is for visual motion - how spatial information changes over time - it might be expected that static and time-varying concepts require equal attention. Both require definitions of their properties as well as relationships. In the spatial domain, those relationships deal with how different parts might be arranged in relation to one another. In the temporal domain, those relationships involve how events might be arranged in relation to another - temporal order and continuity. Both spatial and temporal concepts can be defined at different levels of abstraction and these can be organized along a specialization dimension. Finally, spatial and temporal concepts can be defined by comparing one to others. That is, if it is the case that two concepts are very similar except for a small detail or two, they can be linked by those differences and during interpretation they would naturally arise as competing hypotheses that can be differentiated by confirming those differences.
The resulting interpretation strategy (from Tsotsos 1980) is:
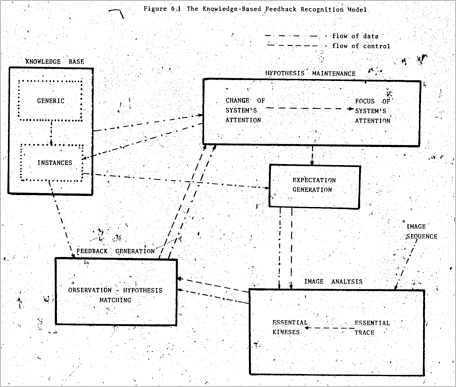
It is interesting to note that the overall strategy included specific components to change and focus the system’s attention in hypothesis space, to generate hypothesis-specific image expectations from that focus into image space, and to provide feedback to the attention system based on success of matching hypotheses and data. In these respects it pre-dates the active vision paradigm in its control of data acquisition and pre-dates all computer vision attention methods. The method for determining the focus of attention was based on competition among hypotheses, formulated using relaxation labeling, and thus was a generalized instance of the now-classic lateral inhibition.
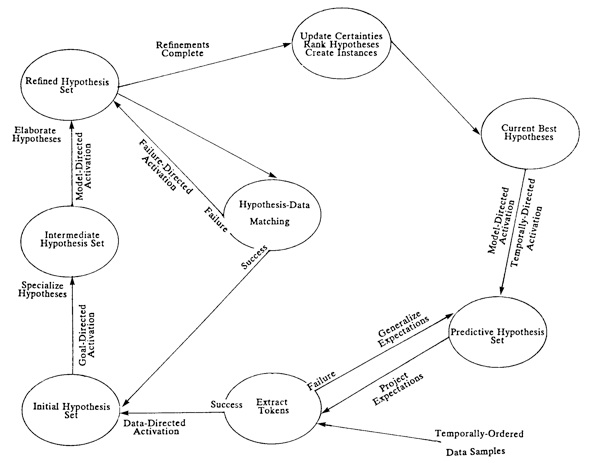
This control strategy was updated subsequently to show more detail for each stage (shown below, from Tsotsos 1985), and especially to highlight how control used the concept organizational dimension in an integrated manner: movement of control up or down the parts hierarchy is model-directed activation, movement down the specialization dimension specializes hypotheses while movement up generalizes expectations; movement along the temporal organization leads to temporally-directed activation, and movement along the competition dimension leads to failure-directed activation. Data and goal direction is also present.
More detail can be found in:
Tsotsos, J.K., A Framework for Visual Motion Understanding, PhD Dissertation, Dept. of Computer Science, University of Toronto, 1980.
Tsotsos,J., Mylopoulos,J., Covvey,H.D., Zucker,S.W., A Framework for Visual Motion Understanding, IEEE Pattern Analysis and Machine Intelligence, Special Issue on Computer Analysis of Time-Varying Imagery, Nov. 1980, p563 - 573.
Tsotsos, J.K., The Role of Knowledge Organization in Representation and Interpretation of Time-Varying Data: The ALVEN System, Computational Intelligence, Vol. 1, No. 1., Feb. 1985, p16 - 32. , Re-printed in Readings in Computer Vision, pp. 498 - 514, ed. by M. Fischler and O. Firschein, Morgan Kaufmann Press, 1987.